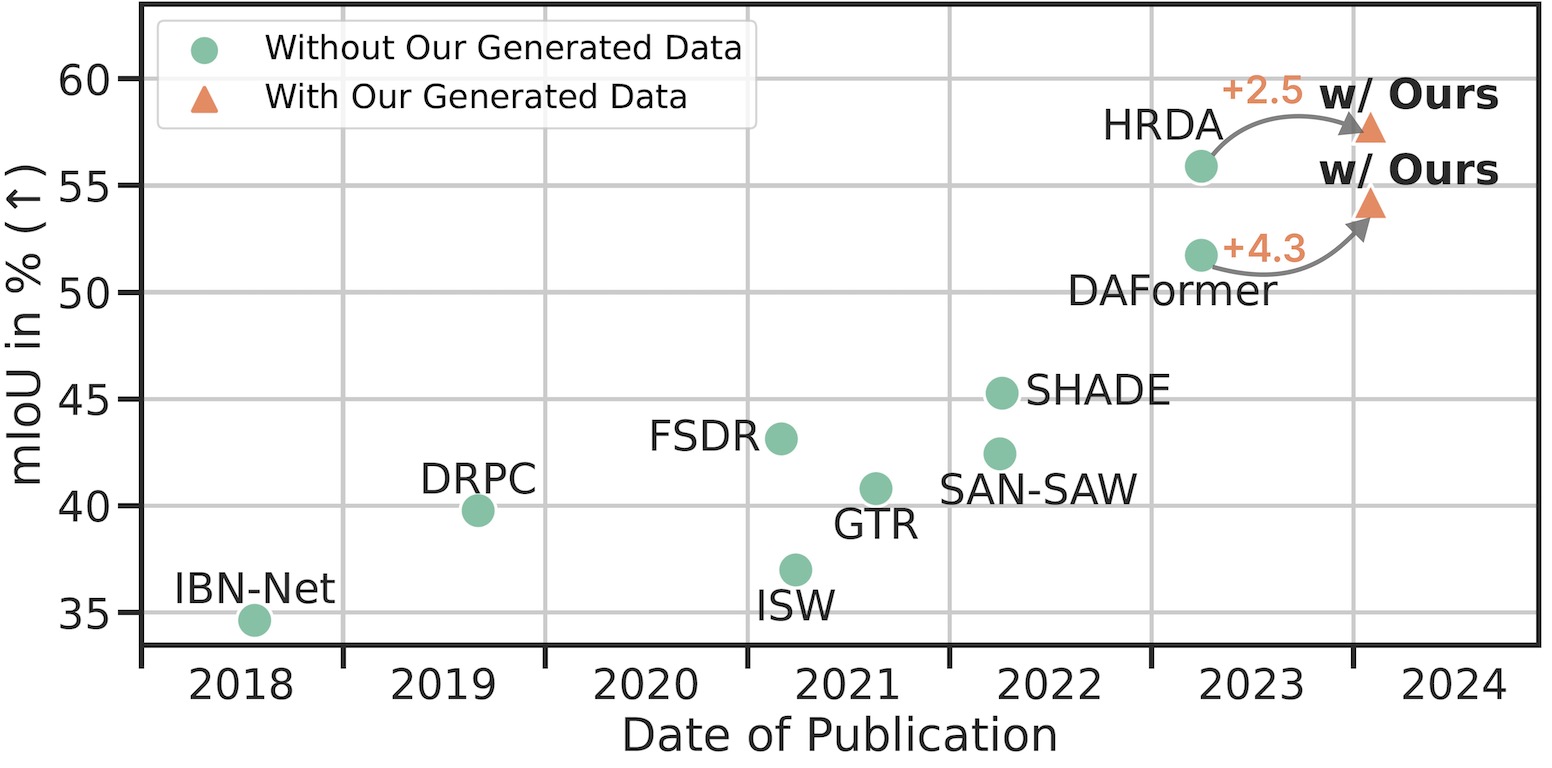
Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding "yes". We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Third, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods, in some cases by +2.5 mIoU compared to the previous state-of-the-art method without our generative augmentation scheme.
When training on synthetic data, ControlNet learns not only to control but also to steer the generation style toward the synthetic domain. This issue constrains the quality and diversity of the output generation and hinders the usage of the rich generative prior to the full extent. The style drift issue and the way DGInStyle addressed it are exemplified in the figure below.

Stable Diffusion operates in the latent space, and therefore, its effective resolution is limited. We pay special attention to small instances when generating high-resolution images conditioned on high-resolution semantic masks. Such attention helps with the coherency of the generated data and improves downstream applications, such as semantic segmentation. The small instances issue and the way DGInStyle addressed it are exemplified in the figure below.

Refer to the pdf paper for more details on qualitative, quantitative, and ablation studies.
We train multiple state-of-the-art Domain Generalization solutions for semantic segmentation with DGInStyle and obtain superior performance.
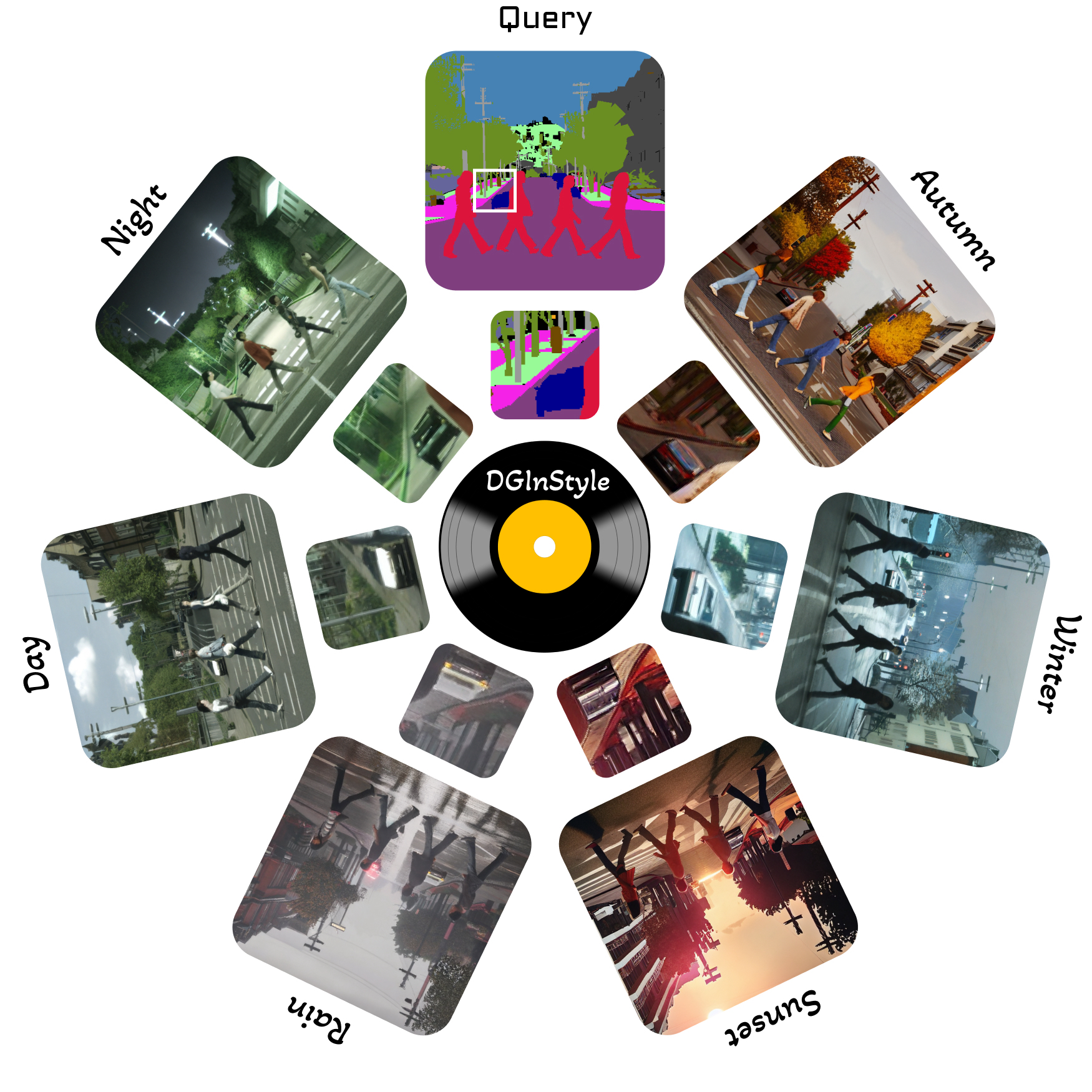
Each mask can be used with multiple freeform text prompts to diversify the generated data and enable domain generalization in downstream tasks. This is made possible thanks to the internet-scale generative prior.

Refer to the pdf paper for more details on qualitative, quantitative, and ablation studies.
@inproceedings{jia2024dginstyle,
title = {DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control},
author = {Yuru Jia and Lukas Hoyer and Shengyu Huang and Tianfu Wang and Luc Van Gool and Konrad Schindler and Anton Obukhov},
booktitle = {European Conference on Computer Vision},
year = {2024},
}